



2026年夏天,机器人圈被一个近乎“黑色幽默”的实验结果炸开了锅。
一支由斯坦福教授李飞飞、英伟达具身智能负责人Jim Fan、佐治亚理工学院助理教授徐丹飞领衔,联合Pieter Abbeel、Jitendra Malik、Ken Goldberg、Trevor Darrell等多位顶尖学者的“超级团队”,在一项消融对照实验中遇到了一个百思不得其解的现象。
他们在一个名为π0.5的行业经典模型上做了一件看似理所当然的事——把触觉信号作为额外信息输入给模型。按常理,多一种感知应该多一分精准。结果却令人瞠目:据论文中的消融实验显示,任务成功率从17%骤降至6%。
加了触觉,机器人反而“不会干活”了。
这个反常结果,像一记耳光打在了整个具身智能行业的脸上。过去几年,业界的主流做法是把一切感知信息——视觉、语言、触觉——统统转成同一种格式塞进同一个大模型里,相信“数据多了自然智能涌现”。T-Rex论文用一组冰冷的数据证明:这条路,可能从一开始就走偏了。
触觉为什么成了“猪队友”?
问题出在哪里?论文作者们给出了一个简洁而有力的诊断:频率错配。
据论文及相关技术解读,视觉是一种“慢感知”。摄像头以大约每秒5帧的频率扫描世界,提供的是稳定的场景语义——知道物体在哪里、长什么样。但触觉是一种“快感知”。当指尖接触到物体的瞬间,压力、滑动、形变等信息以毫秒为单位变化,触觉反馈天然需要在每秒20次甚至更高的频率下才能发挥作用。
打个比方:这就像让一个长跑运动员(视觉)和一个短跑运动员(触觉)在同一条跑道上以同样的速度跑步。长跑运动员觉得节奏太快跟不上,短跑运动员觉得节奏太慢憋得慌。把这两种时间尺度完全不同的信号强行塞进同一个以低频运行的Transformer里,结果不是“1+1=2”,而是“1+1<1”——触觉的高频优势发挥不出来,反而把视觉已经学好的表征搅得一团糟。
换句话说,不是触觉没用,是用错了地方。
面对这个结构性矛盾,研究团队没有在原有框架上修修补补,而是选择推倒重来。
他们提出了一套名为T-Rex的全新框架。T-Rex既是“触觉反应式灵巧操作”(Tactile-Reactive Dexterous Manipulation)的缩写,也暗合“霸王龙”之意——虽然霸王龙的前肢短小,但这篇论文要解决的,正是一双灵巧手如何真正“感知”世界。
T-Rex的核心思路可以概括为一句话:别再让触觉和视觉抢同一条算力通道了,给它单独开辟一条独立的高速公路。
具体怎么实现?论文提出了一套混合Transformer专家架构(Mixture-of-Transformers,MoT) 。所谓“混合”,是把机器人的控制权拆解给三位各司其职的专家;所谓“变速率”,是让三位专家各跑各的时钟频率,互不干扰。MoT中的“M”恰好同时代表了这两层含义。
第一位专家负责“看路”和“预判”——它叫潜在专家。 它的任务是处理视觉和语言信息,预测“接下来场景会变成什么样”,为后续动作提供时间上的上下文。说白了,它在提前想好下一步会发生什么。
第二位专家负责“画草图”——它叫动作专家。 它从一片“噪声”开始,通过一步步去噪,生成一个大致的动作走向——“手往这个方向移动”。这个模块的运行频率大约是每秒5次,对应视觉感知的天然节奏。
第三位专家负责“微调”——它叫触觉专家。 它不参与前期的全局规划,只在接触发生的瞬间启动,以每秒20次以上的高频实时读取指尖传来的力和形变信号,在动作专家画好的“草图”上做毫秒级的精细修正——“力道轻一点”“往左偏一毫米”。
三个专家的协同流程是这样的:动作专家先跑完前几步,画出一张动作草图;触觉专家从某个中间节点接手,利用最新的触觉数据完成剩余步骤的精化。动作专家负责“低频去噪”,触觉专家负责“高频精化” 。潜在专家全程“看路”,为两者提供视觉上下文。三位专家各跑各的时钟,各司其职,最后协同输出完整的动作。
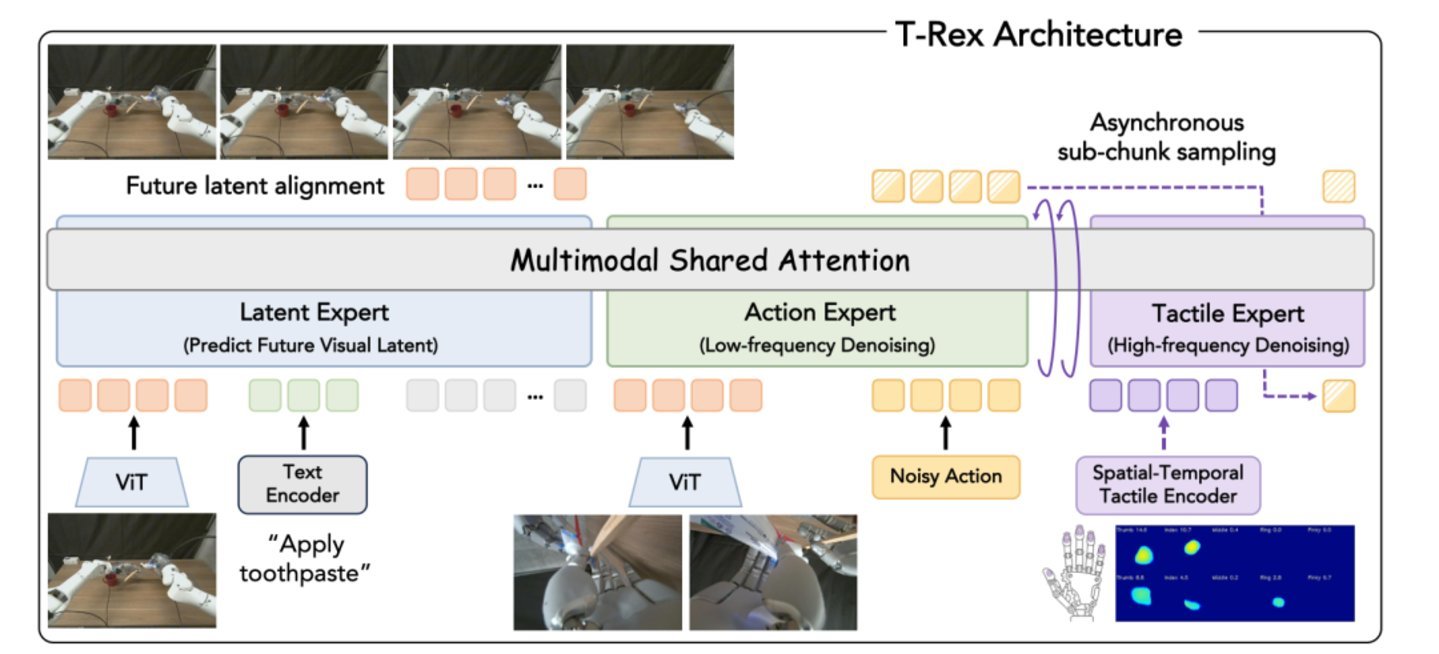
T-Rex 的 Mixture-of-Transformer-Experts(MoT)架构。(图片来源:T-Rex)
为了让触觉专家真正“读懂”触觉信号,论文还专门设计了一套时空触觉编码器。核心是一个VQ-VAE模块——你可以把它理解为一个“翻译官”,把过去十几帧的时序力数据压缩成离散的“触觉词汇”,既能捕捉力的变化趋势,又能抵抗传感器的信号漂移。这样一来,触觉专家接收到的就是一套标准化的“触觉语言”,而非杂乱无章的原始信号。
这套设计的本质,就是给高频触觉信号辟出一条独立的通道,不让它被低频的视觉节奏拖累。 三个专家各跑各的频率,各管各的事,互不干扰,最后再协同输出一个完整的动作——既保留了视觉对全局的把控,又彻底释放了触觉在接触瞬间的敏捷反应能力。
数据层面同样下足了功夫。团队构建了一个100小时的触觉同步数据集,涵盖200多种日常物品、22种动作基元(抓取、挤压、插入、擦拭、折叠等)、7700多条运动轨迹。与传统做法不同,这个数据集不是针对某个特定任务录制的,而是围绕“动作×物体”的组合来组织——22个动作搭配200多种物品,通过排列组合覆盖尽可能多样的接触场景。这让模型学到的是通用的触觉-动作对应关系,而非死记硬背特定任务的模板。
训练策略同样极具层次感。团队先用22,889小时的人类第一视角视频进行大规模预训练,让模型理解人类的手部交互模式;再用上述100小时的机器人触觉数据进行跨模态对齐;最后仅需少量特定任务示范即可完成专项能力的激活。这种渐进式训练的好处是,触觉能力不需要从头学起,而是在视觉运动先验已经建立之后,以相对少的数据“嫁接”进来。
12项“刁难级”任务,30个百分点的跨越
这套架构到底有没有用?论文在12项专门为“刁难”机器人而设计的精细操作任务上进行了严苛测试——翻书页、转移生鸡蛋、擦盘子、挤牙膏、分纸杯、分拣麻将、开锁、填药盒、模拟化学滴定、抽卡片、发扑克牌、拧灯泡。每一项都要求机器人对接触力进行动态的、即时的调节。

T-Rex 完成翻书等接触密集型任务(图片来源:T-Rex)
最终结果令人振奋:T-Rex相较此前最强的基线模型,在这12项任务上取得了超过30%的平均成功率提升。在翻书页、分纸杯等对力度极为敏感的任务中,T-Rex的表现从“几乎不可用”跃升到了“初步具备实用价值”。
进一步的消融实验反向印证了设计的精妙:一旦切除所有触觉输入通道,系统成功率出现断崖式下跌;而如果强行取消异步运行机制,让触觉被迫降频与视觉同步,性能同样会显著劣化。这恰恰说明,T-Rex的成功并非单纯来自“加了触觉”,而是来自“用对了触觉”——给它独立的节奏、独立的通道、独立的处理逻辑。
T-Rex这篇论文的价值,远不止于一组漂亮的实验数据。它用一个极具说服力的反例,向整个具身智能行业发出了一个明确的警示信号:
“万物皆token、一切进大模型”的通用范式,并不天然适用于所有感知模态。
视觉和语言是“慢变量”,适合放在同一个巨大的Transformer里做全局关联推理;但触觉是“快变量”,它关乎物理接触和即时反馈,需要单独的高频闭环控制回路。强行把两者塞进同一个模子,结果不是融合,而是污染。
这让人联想到神经科学中经典的双流假说——视觉腹侧通路负责“识别是什么”,背侧通路负责“指导怎么做”。T-Rex的混合专家架构,某种程度上是在机器人身上复刻了这种生物演化的高级智慧。
当然,论文也坦诚了当前的局限性:对于需要数秒级连贯协调的复杂操作,纯粹的行为克隆仍受限于示范数据的覆盖度;当前触觉感知仅限于指尖而非全手掌,且传感器标定与漂移问题仍是工程痛点。但这些属于“成长中的烦恼”,并不妨碍T-Rex所确立的范式意义。
这篇论文传递的核心信息已经无比清晰:别再让机器人光靠“瞪大眼睛看”来干活了,是时候让它们学会“伸出手去摸”。 触觉不应是视觉的附庸,而应是一条独立的、与视觉平起平坐的物理感知通道。
那个“17%跌到6%”的反常实验,或许正是机器人从“看见世界”走向“感知世界”的关键转折点。(本文首发钛媒体APP,作者 | 硅谷Tech-news,编辑 | 赵虹宇)
本文转自:凤凰网科技
原文地址: https://tech.ifeng.com/c/8uVSsmeNpPQ
小同爱分享1 个月前
命没了还有轮回,钱没了,死都不甘心。 - 小同爱分享
小同爱分享4 个月前
疫情,就是让人抑郁,又没了感情。 - 小同爱分享