


作者 | Tina
2026 年 6 月 15 日,Redis 之父 Salvatore Sanfilippo,也就是 antirez ,在 X 上发了一串推文,情绪罕见地激烈:
“中国模型之所以强大,绝不是因为它们对美国模型进行‘蒸馏’(distillation)。通过 API 进行模型蒸馏是不可能的。如果有人告诉你相反的情况,那说明他们根本不懂机器学习。”
推文瞬间引爆了 X 网友们的敏感神经,于是一场争论又开始了。
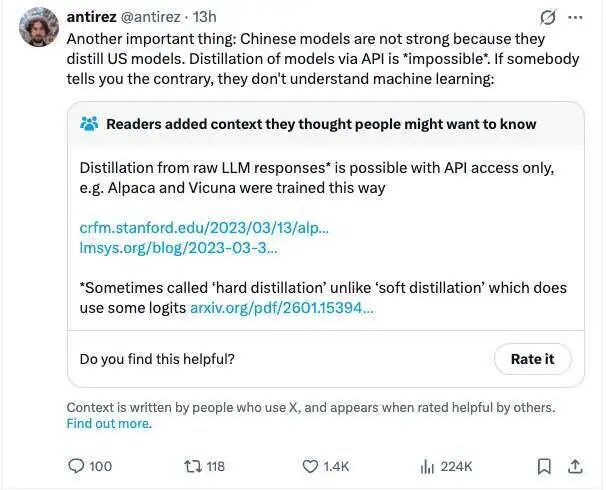
因为他这番话,针对的正是过去一年美国 AI 圈很流行的一种说法:DeepSeek、Qwen、Kimi 这些中国模型进步这么快,都是靠用 API 去“套”美国顶级模型的回答,再拿这些回答来训练自己。
就在 antirez 发推的前两天,Anthropic 针对外国用户,在全球范围内暂停了其前沿模型 Mythos 和 Fable 5 的访问。这一极端举措无疑将“模型蒸馏”的讨论推向了新的高度。
而 Redis 之父,这位在技术圈德高望重的意大利程序员直接站出来说“你们搞错了”。
Redis 之父的“不可能三角”
昨天晚上,antirez 连续发了一长串推文,反驳“API 蒸馏”的说法。他认为首先是“API 给出的数据不够”,要蒸馏一个模型,需要访问海量的、带有完整 logits 的请求,包括思维链的所有中间输出。但通过公开 API,你只能拿到最终的文本结果(相当于看了一眼答案,反推推导过程)。
其次是数学上不成立,这就像在一个极其复杂的曲面上看到几个点,却妄想重现整个曲面。
再次是能力来源需要明确的信息路径。预训练需要数万亿 token,RL 需要探索的奖励信号,完整的 logit 从 o1 之后就不再提供——那所谓“蒸馏”的信息通道到底在哪里?
antirez 还特别提到 DeepSeek。DeepSeek 已经把自己怎么做预训练、怎么做 SFT、怎么做 RL 管线讲出来了,社区里也有人复现出了一部分结果。既然有公开方法,也有可验证的结果,为什么大家宁愿相信“它一定是蒸馏出来的”这种猜测,也不愿相信它真的有能力训练大模型?
以下是 antirez 全部推文的翻译:
第一,真正的蒸馏需要访问极其大量的请求,而且这些请求必须带有完整的 logits,包括生成思维链时的 logits。但现在这些思维链通常已经被总结过了,你根本拿不到完整过程。
第二,通过 API 调用来蒸馏模型,就像你只看到了一个极其复杂曲面上的几个点,却还想把整个复杂曲面复原出来。从数学上讲,这简直是科幻。
第三,DeepSeek 在 R1 论文里做的那些蒸馏,确实提升了目标模型的能力。但那些目标模型本来就已经在大量 token 上预训练过,只是没有接受过“思考”训练而已。潜在能力本来就在那里。即便如此,这些蒸馏出来的模型也谈不上特别强。
第四,你真正能做的,是为强化学习流程获取一些高质量信号。这确实有点用,但并不是决定性的。首先,你得有一套真正跑得起来的 RL 流程,而真正的工程能力也就在这里。
第五,就算你已经拿到了模型,蒸馏仍然很难。现在有很多中国前沿模型是公开可用的,可许多实验室,包括欧洲的一些实验室,仍然做不出和它们对齐的模型。
第六,DeepSeek 已经公开了他们如何搭建预训练、SFT 和 RL 管线的细节。这些结果甚至已经被复现了。为什么你们更愿意相信那些跟风瞎扯的论调,却不愿意相信那些可复现、可获得的结果?他们已经证明了自己能把大模型训练好。
第七,如果还有人坚持这种机器学习上的荒谬说法,你就问他:你声称模型从某个来源学到了某种能力,那请你把信息路径拿出来。预训练?那需要数万亿 token。强化学习加验证器?也没有。那需要来自探索过程的奖励信号。完整 logits?那是老师模型的完整分布,而从 o1 或类似模型开始,这些东西根本就不给你。那么,信息通道到底是什么?
最后他总结道:“别再重复这种胡话了。哪怕你的个人简介里写着‘AI 专家’,你也只是在向全世界证明你根本不懂机器学习。”
但这种表态很快也把火烧到了 antirez 自己身上,推文评论区简直惨不忍睹。有网友说, antirez 明显违反了推特的“第一性原则”:你不能表扬中国模型,永远,否则反对者就会像潮水一样把你淹没!
有人甚至直接在评论区质问他:“谁付钱让你发这个?”
包括他在内的一些网友,是用“指令微调”来反驳 antirez:API 输出当然能训练模型,Alpaca 和 Vicuna 就是早期例子。Alpaca 使用 OpenAI text-davinci-003 生成的 5.2 万条指令数据微调 LLaMA 7B;Vicuna 则使用 ShareGPT 上用户分享的 ChatGPT 对话微调 LLaMA。
但这是实现黑盒蒸馏的操作手段之一:你不需要拿到模型的 logits 或内部概率分布,只需要通过 API 收集大量的 (指令, 输出) 对,就能拿去训练自己的模型。
而 antirez 从头到尾说的“蒸馏”,指的是经典知识蒸馏(白盒蒸馏),需要拿到教师模型的完整 logits 和内部概率分布。他反复强调“full logits”“完整思维链”,指向的就是这个技术范式。在这个定义下,API 确实给不了这些东西。
“蒸馏”这个词被刻意武器化了
还有一些网友引用 Anthropic 的报告作为自己结论的支撑。那份报告指出 DeepSeek 和 Moonshot AI 等实验室进行过大规模查询,很可能就是在收集训练数据。
但这份报告本身就有很大问题。我们曾专门拆解过:Anthropic 指控 DeepSeek 的约 15 万次交互属于“异常规模”。但一个普通 AI 聊天工具日均交互约 16 万次,按 Anthropic 的标准,任何正常产品一天就能“偷走”全部能力。另一个对比是技术评测产生的大量交互。以 SWE-bench 为例,两千多个任务、每个任务调用几十次工具,一轮测试就接近 12 万次。反复调参跑多轮,突破百万次是常态。这些交互完全可以来自正当的评测流程,而非所谓的“蒸馏攻击”。

不过还有两位业界专家不赞成 antirez 对“蒸馏”的定义。
一位是 Redwood Research 的首席科学家 Ryan Greenblatt ,他认为 antirez 的帖子“在事实层面明显错误”,点赞数这么高很离谱,应该加上 Community Note。
Ryan 的主要意见是,antirez 至少采用了一个在大语言模型语境下并不标准的“蒸馏”定义。他还补充说,只用不算很多的轨迹来蒸馏 RL 是很容易证明的,而且已经在很多地方被证明过,这明显和 antirez 这个讨论串的说法相矛盾。
但 Ryan 反驳的是 antirez 对“蒸馏”的狭义定义,本身并不涉及 DeepSeek 能力来源。
另一位是 AI2 研究员 Nathan Lambert,也是刚刚结束中国行的美国学者之一。
Nathan 认为,蒸馏本来是一种通用的后训练技术,但他们却用这个词来指代一个更具体的问题:破解 API,或者说让 API 越狱。另外,蒸馏确实有用,但如果是按预期付费使用 API,“哪怕这违反了服务条款,我也不会太同情前沿实验室因此推动政策行动”。


最关键的一点是,“蒸馏”已经成为了一个“道德术语”。假如真存在“以较少的投资迎头赶上竞争对手”的情况,那么这些企业就会想办法从道德上重新定义这个行为,以维护自身利益。
所以,“通过训练已经解出来的问题来提升模型”这个说法,听起来不够有煽动性。我们需要一个更恶意的词,比如“蒸馏攻击”。
“蒸馏”这个词很好,因为它会让人联想到私酒和 20 世纪 20 年代禁酒令时期那种地下交易的氛围。“攻击”这个词也很好,因为只有坏人才会攻击。于是,你就利用这样一个事实:过去人们把一种技术叫作“蒸馏”,也就是在能够访问大模型内部信息的前提下,用大模型来教小模型;然后你再给它加上“攻击”两个字,让它听起来更邪恶。
Nathan 进一步表示,如果中国模型算是被“蒸馏”出来的,那么 Cursor 对 Kimi 的微调,以及任何在其他模型输出上训练的模型,也都该算“蒸馏”——更何况如今大多数人类输出本身已有模型辅助。
也正因如此,Nathan 明确说,他不会把“在其他模型输出上训练”称为“蒸馏”,而主张叫它“基于模型输出的训练”或其他不带道德色彩的说法。他同时坦言,当前大语言模型的存在本就源于对版权法颇具争议的处理方式,只不过事后因其社会价值而被正当化;但我们绝不能让某些商业利益方,把自己的利益诉求包装成道德框架。
工程师文化,才是真正的答案
就在这场论战爆发前三周,Linux Foundation AI & Data 的 CTO Matt White 和 Nathan Lambert 各写了一篇文章,讲述他们为期八天的中国之行。他们的答案出奇一致,他们看到的中国 AI 实验室,不是一个躲在美国 API 后面抄答案的生态。
Matt White 写到,中国 AI 实验室普遍年轻、精简。他遇到的中国 AI 研究员平均年龄在 25 岁左右。研究员和工程师不太热衷个人品牌,更关心模型能不能真的变强。开源在许多实验室里不是宣传策略,而是默认选项。问题往往不是“要不要开源”,而是“哪些部分开源、什么时候开源”。
他对 DeepSeek 的描述尤其值得注意,“如果说有一个实验室在整个中国 AI 生态中获得普遍尊重,那就是 DeepSeek”。他访问的几乎每一家实验室都会提到 DeepSeek 的创新,尤其是 GRPO 算法和它们在推理训练上的独特方法。这种尊重不是嫉妒,而是对“改变了游戏规则的人”的认可。
Nathan Lambert 则在文章中写道,中国的 LLM 社区“感觉更像一个生态系统,而不是相互争斗的部落”。许多实验室都尊重 DeepSeek,认为它“拥有极佳的研究品味和执行力”。
这些 AI 实验室已经拥有世界级的预训练、RL 和后训练能力。DeepSeek 公布的 GRPO、Muon 优化器、VERL 框架,都被全球实验室采纳。今天构建最好的大模型,越来越依赖整条技术栈上的细致工作:数据、架构细节、RL 算法实现、评测、推理系统,每一个环节都可能带来提升。
从技术能力上,这已经足够说明中国实验室根本不需要靠蒸馏来追赶。中国实验室之所以追得快,很大程度上不是因为某个神秘捷径,而是因为这些团队非常适合做这种密集、复杂、需要大量非光鲜工作的工程优化。
这正好解释了为什么“蒸馏论”不足以解释 DeepSeek,也是 antirez 最不满的地方。
而且 antirez 不只是一个旁观者。不久前,他还亲自围绕 DeepSeek 做过推理工程,开源了 DS4 项目。这个项目是一个专门面向 DeepSeek V4 Flash 的本地推理引擎,优先为该模型优化,也支持在高内存机器上运行 DeepSeek V4 PRO。
也就是说,他真正摸过模型部署的底层问题:模型架构、MoE、长上下文、KV cache、硬件适配、量化、推理效率。对于一个系统程序员来说,一个模型到底只是靠输出样本堆出来的壳,还是背后有真实的架构和工程含量,感受会非常直接。
所以,总结来说,这场争吵最大的分歧在于“蒸馏”的定义。但问题的关键早已超出了技术范畴。真正让 antirez 发声的,是舆论场中一种根深蒂固的预设——只要是中国团队的进步,就必然来自某种“非正当手段”。这种预设无视了中国实验室在算力受限下做出的架构创新、算法突破和开源贡献,把所有进步都归因于“抄袭”。
参考链接:
https://file.tonglife.net/images/16/76b241ad34ddd63a31ccc9259c9059.jpg
本文转自:凤凰网科技
原文地址: https://tech.ifeng.com/c/8tyNCvcMxI0
小同爱分享1 个月前
命没了还有轮回,钱没了,死都不甘心。 - 小同爱分享
小同爱分享4 个月前
疫情,就是让人抑郁,又没了感情。 - 小同爱分享