


IT之家 2 月 3 日消息,科技媒体 9to5Mac 今天(2 月 3 日)发布博文,报道称苹果公司携手特拉维夫大学,联合发表论文,提出名为“原则性粗粒度”(PCG)的语音生成新方法,从而解决 AI 文本转语音(TTS)技术的速度瓶颈。
IT之家援引博文介绍,在生成语音方面,目前行业主流采用“自回归模型”,采用“逐个预测”的方式,即基于已有的 tokens 来预测下一个。
然而,这种机制要求预测结果必须“精确匹配”预设的 tokens,导致模型经常拒绝实际上听感差异极小、完全可用的预测结果。这种过于严苛的验证标准,直接拖慢了整体的生成速度。
研究团队为了解决上述问题,提出了“原则性粗粒度”(Principled Coarse-Graining,简称 PCG)技术。该技术的核心逻辑在于“求同存异”:研究人员认为,不同的声学 token 往往能产生几乎相同的听觉效果。
因此,PCG 不再将每个声音视为完全独立的个体,而是建立了“声学相似组”。只要模型生成的预测 token 落在正确的“相似组”范围内,系统就会予以采纳。这种灵活的验证机制,本质上是将严苛的“单点验证”升级为了容错率更高的“范围验证”。
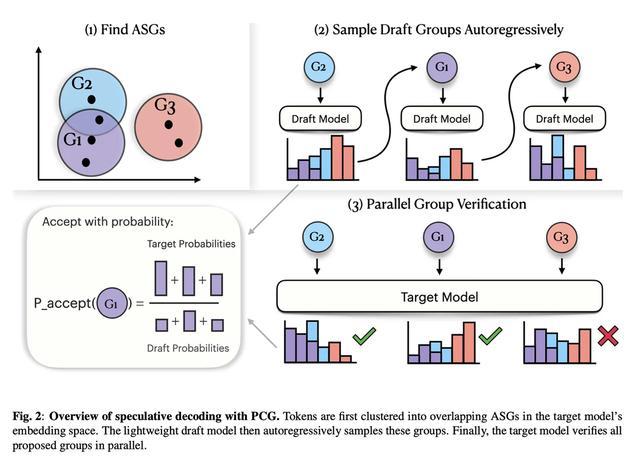
在具体运行中,PCG 引入了“投机解码”策略,构建了一套双模型协作架构。首先,由一个轻量级的小模型快速“猜测”并提出候选语音 token;随后,由一个参数更大的“裁判模型”进行审核。
只要候选 token 属于正确的声学组,大模型便会“放行”。这种分工不仅保留了小模型的高速度,也利用大模型保障了输出质量,有效平衡了效率与准确性。
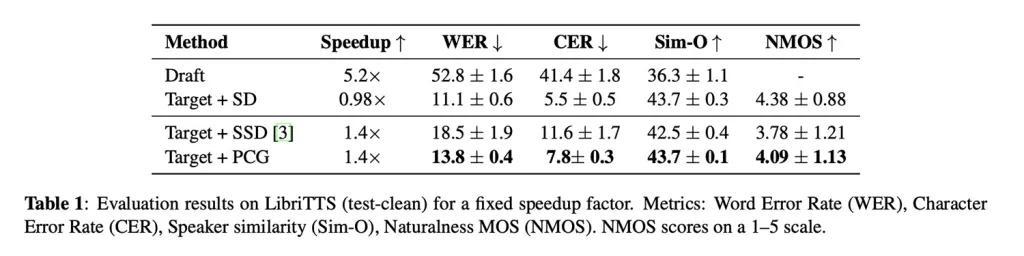
试验数据显示,应用 PCG 技术后,语音生成速度提升了约 40%,且并未牺牲音频质量。在自然度评分(满分 5 分)中,该模型取得了 4.09 的高分。
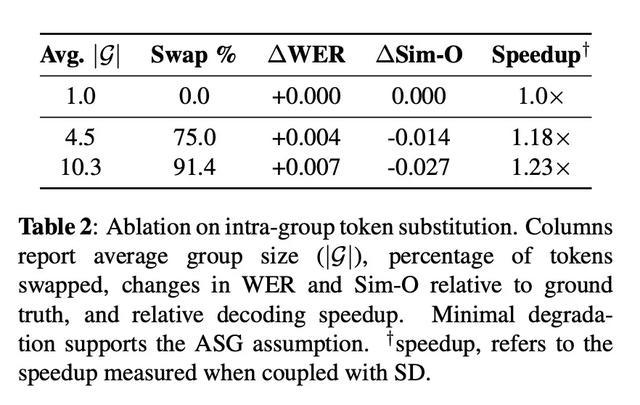
在一项极限压力测试中,研究人员将 91.4% 的语音 token 替换为同组的其他 token,结果显示词错率仅增加了 0.007,说话人相似度仅下降 0.027,人耳几乎无法察觉差异。
PCG 属于“推理阶段”的优化方案,意味着无需对现有模型进行耗时耗力的重新训练即可直接应用。此外,存储声学相似组仅需约 37MB 的额外内存。
本文转自:凤凰网科技
原文地址: https://tech.ifeng.com/c/8qR7fdBmqxk
小同爱分享2 个月前
命没了还有轮回,钱没了,死都不甘心。 - 小同爱分享
小同爱分享5 个月前
疫情,就是让人抑郁,又没了感情。 - 小同爱分享