


最近几天,一张开源模型的等级列表在 X 上被疯狂转载。

图片来源:https://file.tonglife.net/images/6c/bbd0bbb3ec0180ace9bfe953c86cd2.jpg
从夯到拉,国产开源模型排在了数一数二的位置, DeepSeek、Qwen、Kimi、智谱、还有 MiniMax 是全球开源模型的前五名。
而 OpenAI 排在了第四梯队,小扎的 Meta,挖了硅谷半壁江山想打造的 Llama 更扎心,只落得了一个荣誉提名。
这份榜单并不是国产模型花钱打广告,也不是咱中国人王婆卖瓜,自卖自夸。知名的 AI 研究员 Nathan Lambert 和德国 AI 研究中心的博士生 Florian Brand,在 interconnectai 上的一篇文章,给出了全球开源模型的完整排名。

Nathan Lambert 曾在 Meta、DeepMind、和 Hugging Face 工作
文章里详细回顾过去这一年,全球开源模型的发展,以 DeepSeek 和 Qwen 为主的国产开源模型,正在用开源改变整个 AI 行业的运行规则。
事实也如此,2024 年对于全球开源来说,可能还是 Llama 的天下。到了今年,国产开源以一种不可忽视的姿态,持续刷新着全球大模型的默认选项。
性能、价格、生态、可用性……每个维度都在快速逼近闭源巨头,甚至在某些方向已经实现了反超。

上下更多内容,全球开源模型发布历史,2024.01-2025.11,
图片来源:https://file.tonglife.net/images/22/522e75fc727df10048bd1714fc66c0.jpg
当我们还在想国产模型什么时候能追上 ChatGPT、Gemini 时,AI 的军备竞赛场上,另一个问题也开始沸腾起来,为什么全球开发者都在用国产开源模型?
开源模型,前浪后浪一起上
过去这几个月,国产开源模型的更新节奏几乎没有停过。而且不只是某一家模型公司的爆发,是整个国产开源生态,持续接力,就像一条快速攀升的曲线,不断在突破瓶颈。
11 月,Kimi 发布了万亿参数的混合专家模型,Kimi K2 Thinking,直接拿下多个榜单第一名,甚至超过了 OpenAI 的 GPT-5 和 Anthropic 的 Claude 4.5。
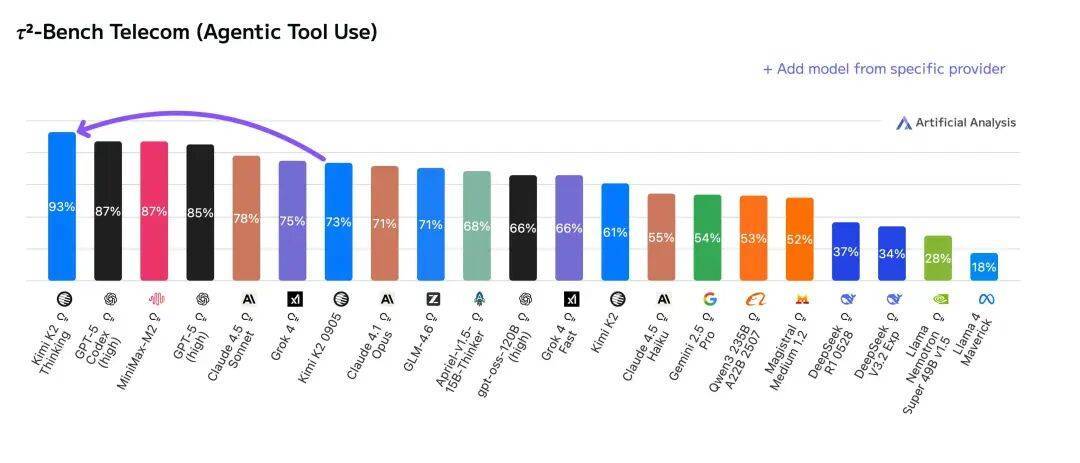
10 月底,MiniMax 正式发布了 MiniMax M2 混合专家模型 MoE,和 Kimi 一样,继续开源,在综合榜单上的表现,MiniMax M2 排名第五,超过了 Gemini 2.5 Pro 和 Claude Opus 4.1。
9 月,阿里在云栖大会上,一套模型七连发的组合拳,在视觉、语音、推理、编程等多个领域做到极致。
海外社交媒体上,关于国产开源模型的认可,从横空出世的 DeepSeek 以来就没停过。「 好用、便宜、小公司的开发首选、自己做的副业项目,用的就是中国开源模型……」,这些评论在 X 上随处可见。
像是网友们对 Kimi K2 Thinking 写作风格,以及用 token 数量换思考深度的称赞。
还有网友说拿 Minimax M2 和 Claude Sonnet 4 对比,M2 只用一次就能生成一个功能齐全的网站,但是 Sonnet 4 会失败。

上下更多内容
关于 Qwen 的帖子就更多了,从 2.5 更新到现在的 3.0,从大尺寸的 4800 亿参数,到只有 6 亿参数的小模型,从视觉语言 Qwen 3 VL,到代码编写 Qwen 3 Coder,开源市场几乎都有 Qwen 的影子在。
爱彼迎 CEO 在接受采访时,甚至大方的表示 OpenAI 虽然好,但是不适合我们;而来自中国的开源模型 Qwen 非常好,能实际地应用到他们的工作中,比 OpenAI 更好更便宜。
在开源这块,说国产开源模型还在追赶都不贴切,是已经实打实地成为了全球默认的开源选择。
MiniMax M2,能落地的开源智能体
如果要用具体案例,来说明国产开源模型,到底好在哪里,过去我们分享的多个开源工具的实测体验,其实就已经有了答案。
发布时间最近的 Kimi K2 Thinking,一次性能执行 300 次工具调用的超长思考链条,还有为手机而生的通用 Agent,智谱 AutoGLM 2.0;以及 AI 时代的安卓,阿里通义模型大家族。
Artificial Analysis 统计的 2025 Q1 国产前沿 AI 模型大厂和初创公司
这些模型虽然都是开源,但是都有各自的技术亮点,努力让国产开源模型这张地图,变得更完整、更丰富。
像 K2 Thinking 主打万亿参数大模型,然后还有自己的 KDA(Kimi Delta Attention)机制;DeepSeek 主打混合注意力,成本骤降;Minimax M2 在这次的更新里面,反而是一改常态,使用了完全注意力,模型参数也仅 2300 亿。
M2 好不好用,本着能体验都上手试试的原则,我们也简单测了一下。
第一个任务是让他处理 Excel 表格数据,我们把今年国考的岗位信息表格发给他,让它根据表格内容,设计一个通用的公务员岗位筛选工具。
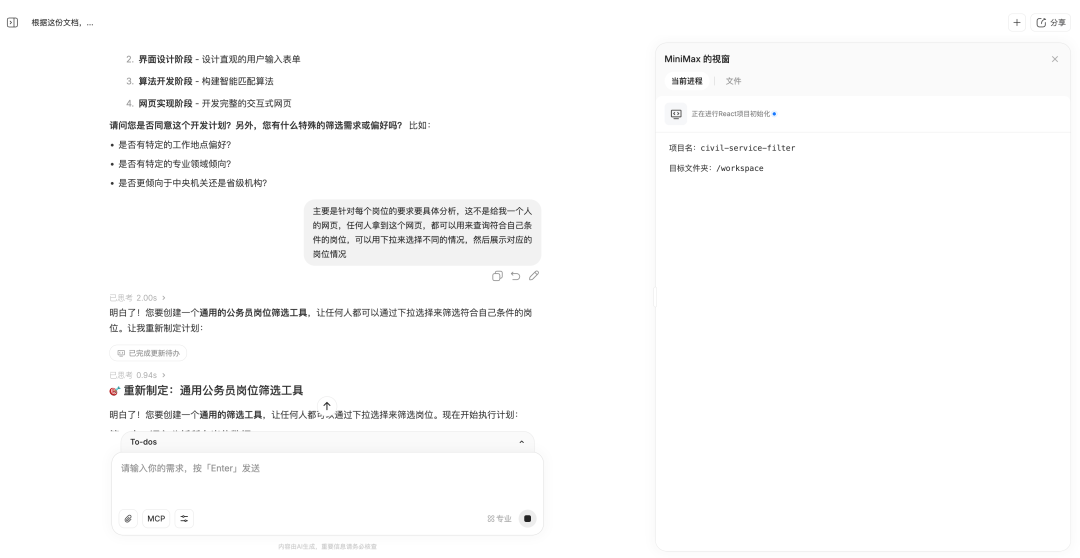
表格的数据非常多,大小有 10MB,累计两万多个岗位。MiniMax M2 特别好的一点是,它会在正式执行任务前,询问用户,是否需要对任务进行调整。
在他们的技术博客里面提到,M2 此次采用了「交错思考」的技术,这项技术最早是在 Claude Sonnet 4 模型中开始应用,但具体的采用还很有限。
MiniMax 给了一个小贴士,提醒用户保留模型的思考记录,即 think 标签。M2 依赖于交错式思维,上下文就是为记忆,保留了,才能更好的开展交错式思考。

上下更多内容,MiniMax 工程主管发 X 解释,交错思考如何让模型更好地完成智能体任务
简单来说,交错思维(Interleaved Thinking)就是让大模型在「动手做事(用工具/调用接口),停下来想一想再动手,然后接着再思考」,这样的循环里推进任务,而不是先把一大段思路想完再一次性执行。
最近更新的 Kimi K2 Thinking 同样采用了交错式思考的技术。边思考边调用的方式,能让模型在每次拿到工具输出后,立刻复盘、调整计划,这特别适合流程长、结果不确定的智能体任务。
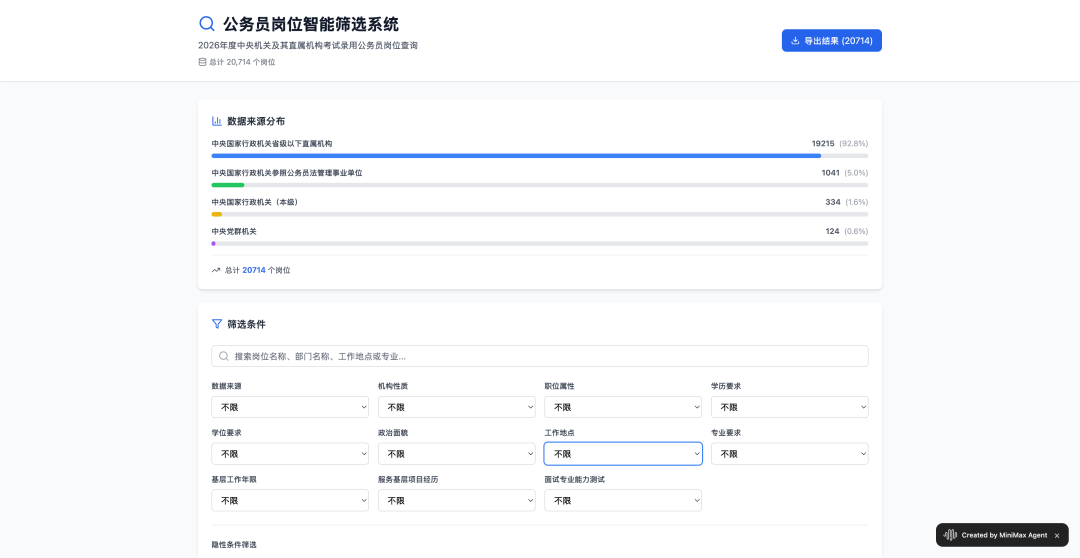
体验地址:https://file.tonglife.net/images/82/75566c8eb46260df73e7540eeb1098.jpg MiniMax M2 处理 Excel 表格数据的能力,不容小觑
最后给出的结果是非常的准确的,20714 个岗位,以及对于应届生、基层工作年限、户籍地等方面的条件,它都有统计到;相比市面上一些付费的选岗工具,自己用 Agent 自动生成一个,再方便不过。
我们还让它去做一些深度研究,丢给它关于 M2 自己的信息,让它制作一个精美的 PPT。
预览链接:https://file.tonglife.net/images/11/8a72db8ef121c9a106418fbe5f1dea.jpg
除了这种从零开始做一个产品的 vibe coding 体验,MiniMax 还提供了详细的教程,关于如何接入 Claude Code 等命令行工具,或开发平台 Cursor、VS Code 等。
使用 MiniMax M2 模型 API 的 Claude Code
交错思考能让模型更聪明,知道何时该调用何种工具。但 MiniMax M2 这次在技术上还有一个亮点,是它一反常态的使用了全注意力机制。
之前我们介绍过 DeepSeek 能把成本打到这么低,其中最重要的原因之一就是它采用了稀疏注意力,以及混合注意力机制。稀疏注意力能让模型在处理 token 时,和我们人类一样,有选择的聚焦在重要信息,而忽略掉次要信息。
配合其他的策略,就能在不影响输出质量的前提下,提升模型的推理速度,降低成本。

本文转自:凤凰网科技
原文地址: https://tech.ifeng.com/c/8p9IPWEVAAR
小同爱分享1 个月前
命没了还有轮回,钱没了,死都不甘心。 - 小同爱分享
小同爱分享4 个月前
疫情,就是让人抑郁,又没了感情。 - 小同爱分享